Venture capital (VC) is traditionally a people-based, non-scalable business. Do you want to do more deals? Hire more people. Want to do deals in a new region? Open a new office. Want to provide better support to your founders? Hire an ops team.
For an industry that invested billions of dollars in technology companies, the venture capital industry lacks proper technology adoption. It is one of the last industries to embark on the digital transformation journey.
The old VC process is broken. It is manual, inefficient, reactive, subjective, and biased at every process step. From sourcing to screening and due diligence, from portfolio support to follow-on and working towards an exit: it is repeating the same people-driven, manual processes repeatedly.
To counter this, most VCs started on a journey toward digitization. Some already many years ago, others only recently. And the industry is scattered in its approach and digitization stage.
Andre Retterath describes this well in his ‘Data-driven VC Landscape’ report:
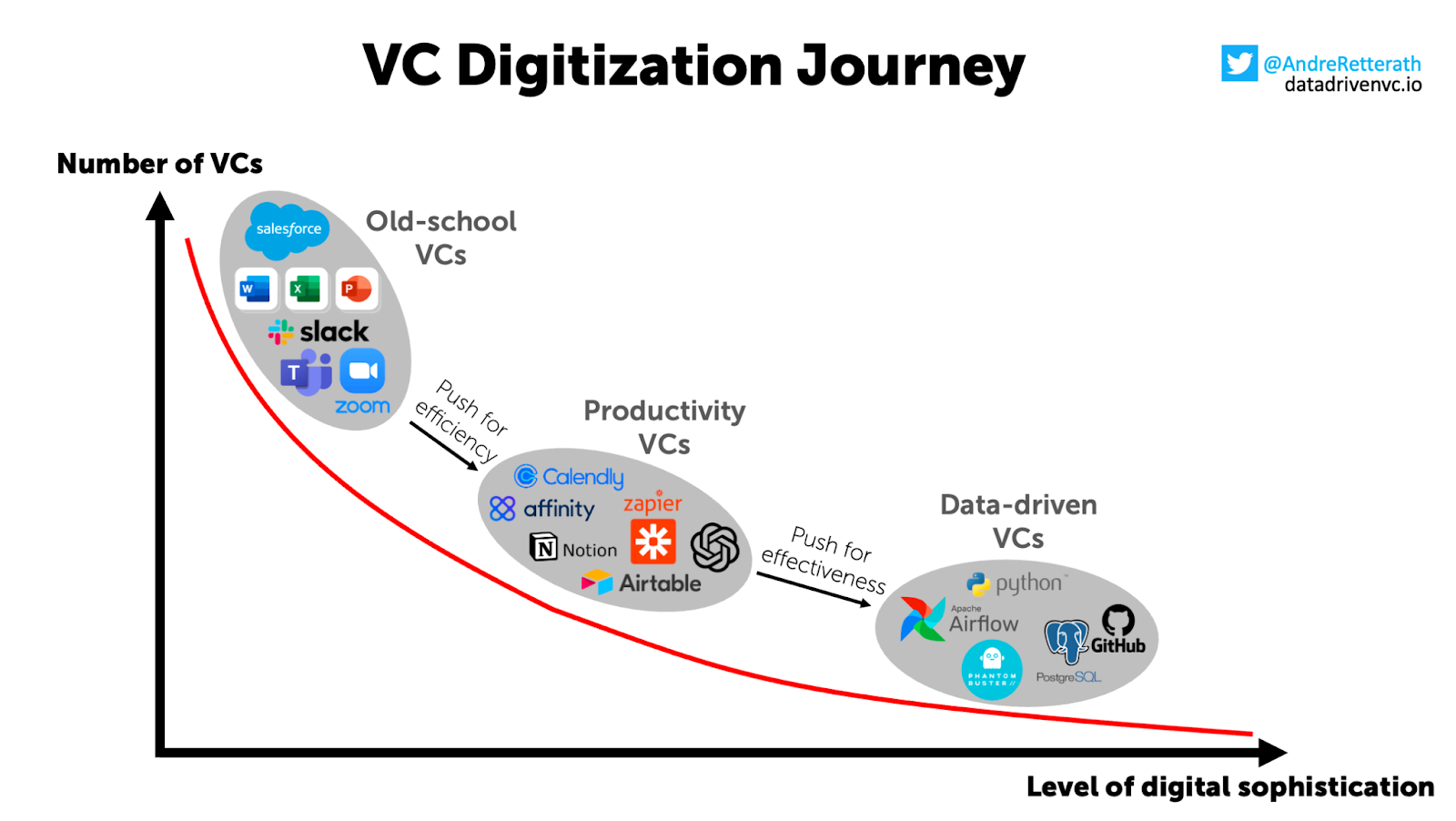
The majority of VCs only just recently started to take the step towards digitization by focusing on improving their manual workflows by introducing classic CRM systems and better communication tools. In their push for more productivity, other VCs introduce modern CRMs, sometimes optimized for the VC use case, or create their CRMs on top of Airtable and introduce workflows with the help of Zapier and other tools.
And then there are a few VCs that take it a step further. They hire engineers to create their solutions to capture data, automate workflows, and bring the core of their business in-house; these are the real data-driven VCs.
We at RTP embarked on a similar journey roughly ten years ago by introducing the first CRM system and groups to communicate internally and externally on WhatsApp and Telegram. Later, we switched CRM systems to a VC-focused CRM, created our first playbooks to be shared with founders on Notion, and started automating some of our sourcing through Zapier workflows.
Three years ago, in the Summer of 2021, we took the most ambitious step. We hired the first engineers to start our journey to become a genuine data-driven VC by building our vision of the Venture Capital Operating System, starting with the first pillars: sourcing and screening. This kicked off by creating our in-house data insights platform: The Beast, and creating the first version of our screening model, Athena, to help us find the best founders as early as possible.
Why did we decide to do this? In short: our ever-growing ambition. Our firm was growing: we launched a new $650M early-stage fund, RTP III, two years before, had an Opportunity Fund in the pipeline, and we knew that given our pace of investing, we would add RTP IV within three years, with a fund size around the $1B mark (and we actually launched RTP IV).
It is not difficult to deploy these amounts of money. However, deploying that kind of money to only the very best founders and startups is challenging. We already grew our team five times to 35 people and opened new offices in New York City, London, Bangalore, Dubai, Paris, and Amsterdam. RTP as a firm grew by being lean and agile, and we didn’t want to lose that advantage by growing our team even further. But we knew we needed to do more, be more efficient, be more effective, and continue to be inclusive as something that was always one of our main differentiators: being an early investor in new markets, first-time founders, and one of the few investment teams where half of the partnership is female.
Our main drivers for investing in our data strategy:
- The number of successful startups is growing faster than ever. We want to ensure we see the best companies as early as possible. Especially since our focus is widening (region-wise and sector-wise).
- Founders are more diverse than before in location, market, founders’ background, etc. We want to ensure we have a non-biased view of the world and have actions and data speak louder than opinions, schools, networks, or colored lenses.
- Time to success, and with that, time to invest, is shortening. It takes fewer years for the break-out hits to reach a $bn valuation.
- There is more competition, ranging from a growing number of pre-seed / seed micro VCs to large growth-stage VCs moving to an earlier stage. If we want to stay ahead, we need to do more than them and be more innovative than them.
- We started experimenting with non-linear scaling approaches, kicking off projects that will deliver us returns not in months but in the coming years. And fitting perfectly well into this is our belief in the power of data: capturing this earlier would create a long-term competitive advantage
We also believed that the moment was now, Summer 2021. Our firm was ready. And we did see that the amount of available data on companies, people, and markets is increasing exponentially. We knew we could not continuously and unlimitedly scale in people. We can use technology to help our people spend their time creating meaningful relations, and working on focused reachouts instead of sifting through data manually. And the right technology can help us find insights from the available data, supporting us in knowing where to focus our efforts and avoid blindspots.
The Beast & Athena
We started by looking at what is already available out there and evaluated multiple products: so-called ‘data banks,’ ‘startup discovery platforms,’ ‘alternative data sources,’ and ‘data platforms’ catering to VCs with the promise to “make them” data-driven. We quickly decided that would not work for us. If we truly believe in the power of data, we need to hold the data ourselves in-house. And we want to make sure we create a screening model optimized for us, not for multiple other VCs. What is the benefit of a data strategy if you act on the same signals presented to many other competing VCs that purchased the same product as you? Why help optimize someone else’s model, making you lose all your data if you switch platforms or vendors? What happens if the vendor you pick changes their strategy, maybe even becoming VCs themselves once they have proven their model?
With the first engineers joining our team, we went for a strategy that enabled us to control our destiny. Yes, it will take longer to build, but venture capital is a long-term game with long-term gains in data and platform investments. And now, three years later, seeing the results (and ad hoc benchmarking against new data platforms popping up), we are pleased that we made that choice back in 2021.
So what did we build? Enter the Beast: The Beast is a data insights platform that brings together as much possible useful information on talent, founders, and companies. Our database continues to grow over time, but at the moment, we track 180k+ companies and almost 900k+ people. This on 250+ data features (think things like LinkedIn employee data, past funding data, but also X sentiment, social mentions, Producthunt and Reddit fame, Github traction, App/Web visits, App Store reviews, call transcripts, pitch decks, etc.), and have gathered over 90+ million data points over the past three years, and that is where the real value comes in: with every data point, over time, the system gets better and more insights can be retrieved out of the data, insights are accelerated over time. But data alone is not very useful; we want to get from data to actionable insights (hence the data insights platform, and not just a data platform or a big data lake).
In using our data and moving from data to actionable insights, we focus on two things:
- Show a complete but also summarized picture of a person or startup to our deal team. This is to give them a direct insight into a founder or startup’s current, past, and future status. This includes the data we collected, growth trends, and proprietary scores we created and brings together insights from multiple other systems in one interface (think e-mail, meeting notes, call transcripts, pitch decks, etc.).
- Raise relevant signals to our team at the right time. This is very much focused on identifying early signs of break-out success, and our best signals combine multiple data features into one meaningful signal. In other words, a fast-growing team is not perse a strong growth signal. But suppose you see a combination of a fast-growing sales team with an increased app traffic trendline, a growing percentage of referral traffic, and exceptional reviews. It might say something about the startup getting closer to product-market fit.
Build vs. Buy
In our platform approach, we opted to build instead of buy. We want to own our data, optimize our model, and create something that brings us the best investment opportunities at the best point in time. Not get the same signals as other VCs using the same product. But while we choose to build for our platform, we are very open to selecting the best vendors to work with to enhance our platform: for data sources and specific tasks and workloads. Of course, we created our proprietary scrapers where this makes sense. But if a great (commercial) API is available for a particular piece of data or data set, we are happy to work with them (and we actively work with 10+ different vendors). As for other integrations: we use Krisp for call transcription and summarization and another vendor’s API to parse through pitch decks and portfolio updates. If there are (open source) great libraries or great APIs available, we opt for integration and not trying to build everything ourselves. We like to focus on where we can make a difference, not reinvent the wheel on infrastructure or areas that are tech commodities now.
What does it look like?
So where are we now? Currently, the tech team at RTP is five people (a mix of engineers and data folks). The Beast comes with a GUI for web and mobile, which is our deal team’s default interface. You can find people and startups and see the data and scores we hold. Our deal team can create and run reports, find personal, regional, and sector signals, and more.
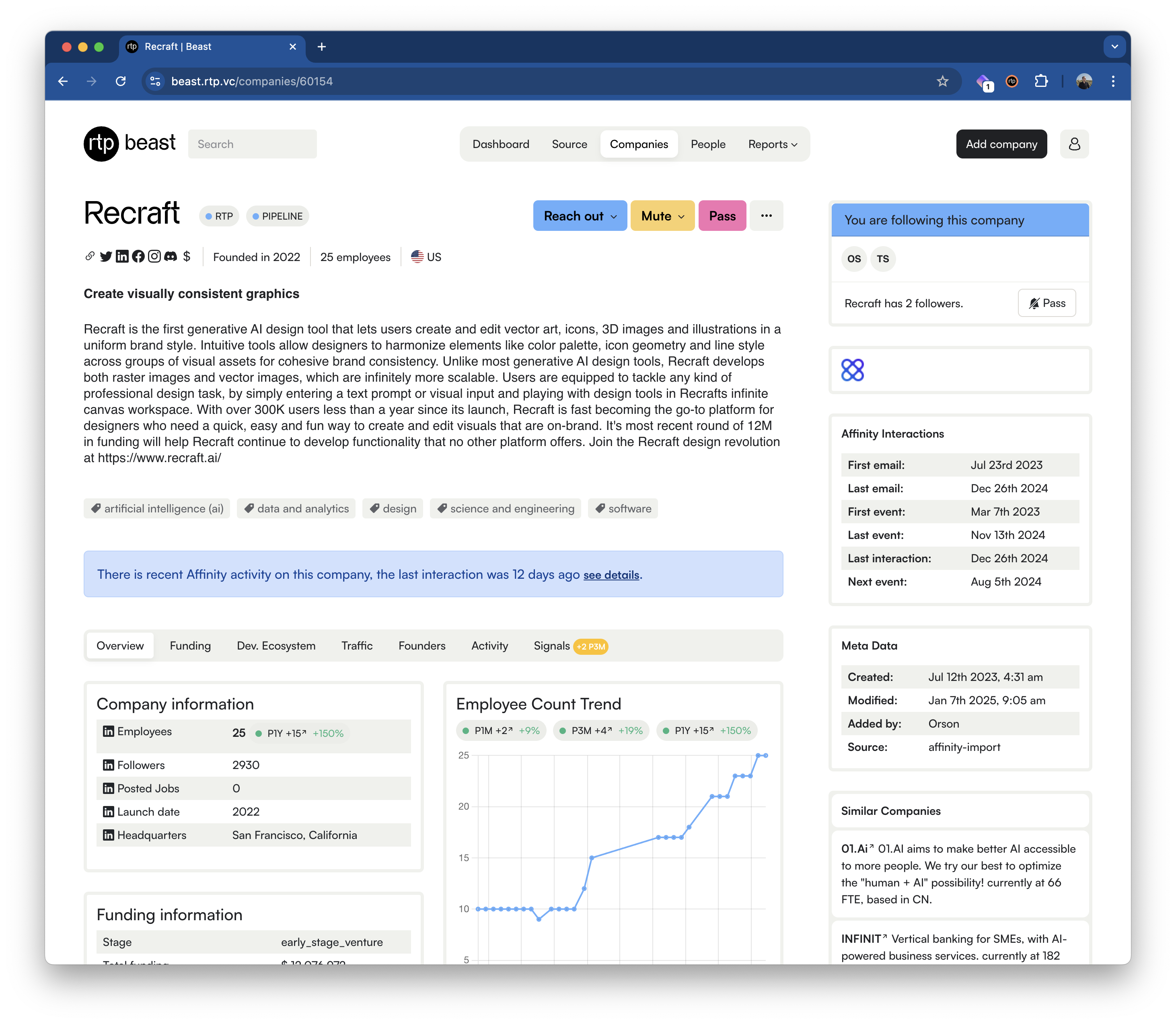
At the same time, we want to ensure that we are as integrated into the day-to-day workflow of the team as possible. For this, we have a strong integration with Slack, where the Beast Bot is an active member in the different deal flow channels, responding to discussed startups and founders with the data that we hold. And push the highest-ranked new signals directly to the relevant team members via a DM. And in their day-to-day browsing, our private Google Chrome plug-in does the same: bringing direct feedback if they visit a startup’s website, a founder’s LinkedIn profile, or Github repo.
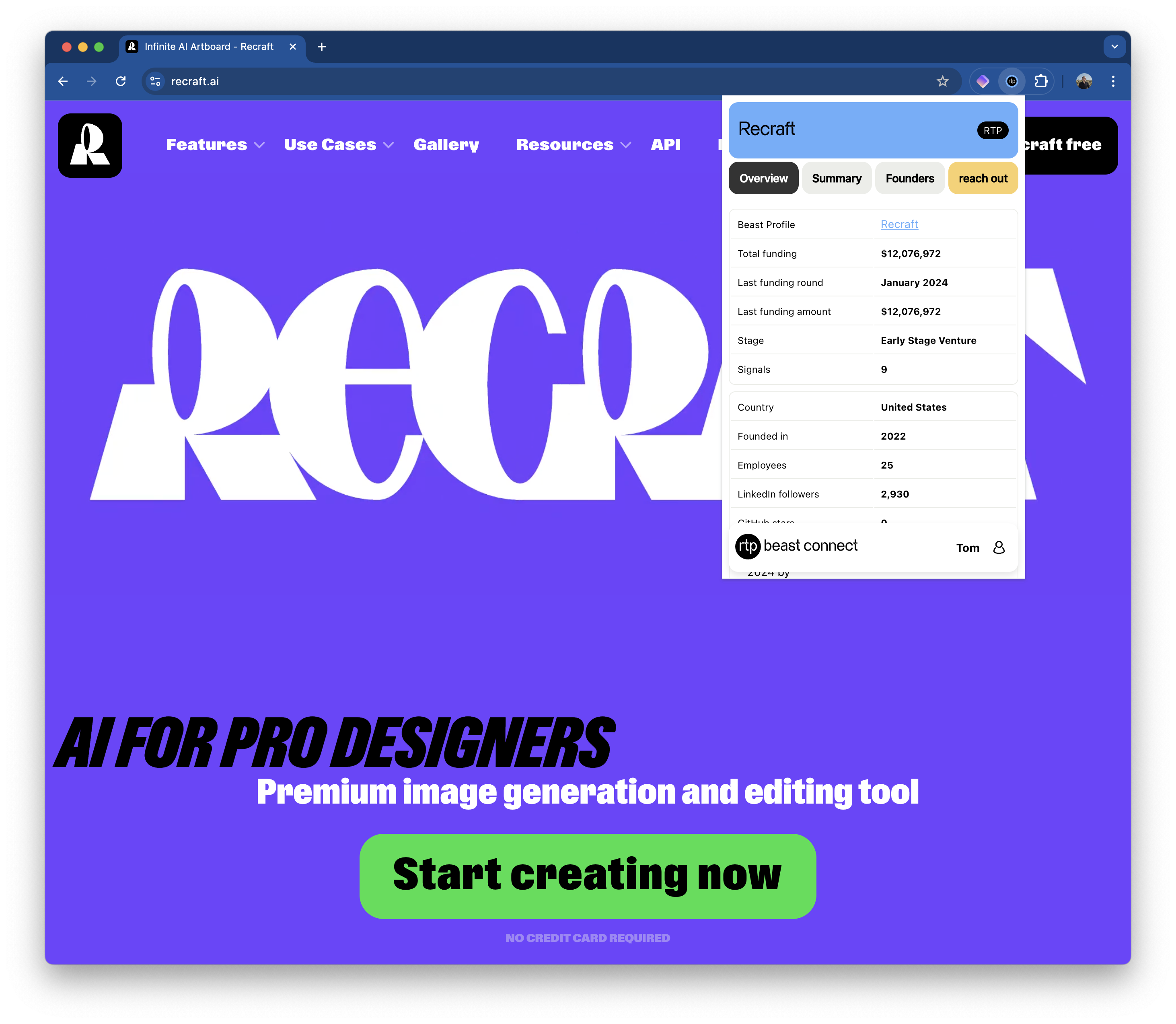
Where the Beast is the data insights platform collecting, storing, and presenting the data that we gathered, Athena is our machine learning model working on top of the Beast, so running on top of our data. Athena has been trained on past VC vintages and achieved in its third iteration the ability to outperform top decile VCs across multiple vintages on Series A deal selection, and she is rapidly improving to do the same for seed stage deals. Of course, making the actual investment is something else outside Athena’s scope, so there is enough work to be done by people after Athena gives her recommendation. We continue to train Athena on new deal data, and feedback gathered through our deal-making process.
Athena shifts through the data we store and works through a sub-set of startups flagged by The Beast on basic signals. The ever-evolving model of Athena then highlights a small set of startups to the deal team regularly, predicting the likelihood of outsized returns. This is the second input to the deal team coming out of our data strategy next to the Beast signals. Athena is continuously updated based on the information gathered during screening, due diligence, and the final decision to do the deal.
Both The Beast and Athena start by gathering and parsing publicly available information, or open-source intelligence (OSINT). But as a VC, you also have more and more access to confidential information. Data coming from pitch decks, coming out during due diligence, and post-investment, from company updates, or if you invest in other funds as well, through fund-of-fund reporting.
We use this confidential information to track the main KPIs for companies we know well and map this against the open-source information we gather online. This is to help the Beast and Athena find the best open source signals with the highest correlation to a confidential metric like revenue, burn, etc. —enabling us to predict the revenue of Seed and Series A startups we evaluate with (higher) confidence.
So that is where we are right now. A tech team of five people created a data insights platform in the form of The Beast, bringing together all the data we gathered (OSINT generating 350+ data features), data we created (scores, signals, notes, transcripts, etc.), and if available direct or predicted confidential information (revenue, cash burn, etc.). On top of this data platform runs Athena, our model that is selecting the best startups, ever-evolving to find the best outliers with the potential to bring us the highest returns.
Measuring success and continuously getting better
An important note to make is that although we try to be as complete as possible in our data gathering, the amount of data we gather is not the goal. The main goal is to identify the best start-ups as early as possible and be able to invest at our preferred stage. So in optimizing The Beast and Athena, we don’t use the number of data points or amounts of terabytes of data stored as a KPI. However, we believe that with more and more data, we get better over time (and see a clear trend line on all KPIs that with data increase and data time coverage increases, we do get better). Ideally, we measure and steer on IRR or DPI, but those metrics take multiple years to mature and will not enable us to act fast enough. So we focus on a few earlier and easier-to-measure KPIs, enabling us to adjust our roadmap and work quicker. Those KPIs are around adoption (weekly active users in the deal team, where we want to score 100%), the ‘signal before outreach rate’ of deals brought to IC (where our data approach is now nearing 50%), and benchmarking against deals announced by what we identified as tier 1 VCs in our regions and sectors. Here we track 80+ VCs and measure ourselves on coverage, signal, and outreach rate. And if we miss a deal, we continuously back-test our data features and signals to see what we can do to be as complete as possible while not increasing our noise ratio.
On that last point: scoring a 90%+ signal rate on every deal ever done is not difficult. Just create a signal for every new domain name registered or updated. However, no team will ever follow up on those signals—too much noise. Therefore balancing signal vs. noise in any data strategy is essential, and a delicate balance: enough signals to not miss the best deals, but not too many to get signal fatigue or see too many startups with a too low-quality threshold.
The Beast also helps us in ensuring business continuity. By growing the team, it is not a surprise that people will leave after a few years. But when that happens, we don’t want to lose their work, their investment in our firm, and above all: their pipeline and network. We realized that leavers created almost half of our pipeline. By redirecting signals on their pipeline back to the regional queue or other team members, we ensure that we do not miss anything they built for us while at RTP. At the same time, we see signal quality becoming on par with insights from long-cultivated relationships: on at least 4 deals in the last 6 months, the Beast predicted and signaled ahead of a heads-up from a friendly VC.
Lastly, we have worked and continue to work with Ph.D. candidates and researchers at different universities, providing our data set as input to get validated research on data-driven approaches in qualifying founders, startups, and more. These works are still being published, but the results are already getting incorporated into the Beast and Athena and will become public in the coming year(s).
Do you even AI?
It is impossible to write this article in 2023 without mentioning AI. And, of course, we should brag about how unique our AI approach is and have our own GPU cluster running. The reality is more boring but definitely more practical.
ML is present in our continuous learning selection model Athena as a subset of AI. We use different libraries and vendors to do specific AI-driven tasks. For example, we work with our portfolio company, Krisp, to benefit from their AI to transcribe and summarize meetings. We work with another vendor to benefit from their AI to gather metrics from pitch decks. We deploy specific agents as part of our data pipelines to improve data gathering and to work on data cleaning tasks.
For fun and games, internally, we are experimenting with a Large Langue Model (LLM) as an extra interface on top of The Beast (next to the traditional GUI, Slack bot, and Google Chrome extension). This is to see if a different way of interacting with the underlying data will bring more or different insights. With the risk of being too hype-driven here and building a lousy chatbot instead of an intelligent AI, it also brings us better knowledge of the ever-growing AI infrastructure landscape we like to look at as investors.
Our Larger Venture Capital Operating System Vision
The Beast and Athena are the first pillars in our larger Venture Capital Operating Vision, the VC OS that fits in our long-term vision and investment of becoming the world’s best tech-enabled VC – something we know cannot be done in a few years but takes, like our investments, multiple years to mature, develop, and become native in the way of working for our teams.
As a data insights platform, the Beast and Athena, as our continuously evolving screening model, focus primarily on sourcing, screening, and some steps in our due diligence process. But we have a larger vision for a complete Venture Capital Operating System (VC OS).
We are working on better tools for our teams to have more and higher quality reachouts. We continuously test the best approaches here and gain more efficiency around the tasks we keep repeating, from scheduling meetings to taking and sharing notes and increasing the quality of our deal memos by automating the mundane parts.
When it comes to portfolio support, we are building tools that enable founders to connect. Connect with us, our larger ecosystem of advisors, and each other. A big part of recurring portfolio support is around playbooks and expert insights. Instead of sharing the best insights individually, we try to get the best nuggets out and make the data more widely available. And a lot of time is spent requesting, chasing, and getting quality intros, with requests getting lost in e-mail inboxes or WhatsApp messages. We are experimenting with better tooling to structure this process to save our founders, our network, and ourselves time, freeing it up for quality interactions.
And on the reporting side, no founder likes being chased for monthly metrics, quarterly statements, or yearly audits. We automate this process as much as possible by improving integrations to the tools they already have in place (Stripe, accounting systems, reporting dashboards) to avoid copy-past work and errors and get it directly from the source. Again, freeing up each other’s time to focus on what matters vs. basic tasks that need to be done.
In all. There are many moving parts, but technology will bring our founders and ourselves a significant advantage. An advantage in quality of work and an advantage of reclaiming time enables us to focus on where people should focus: quality, personal interactions.